PointPillars: Fast Encoders for Object Detection from Point Clouds
2019. 9. 4. 01:41ㆍPaper Review/Pointcloud Learning
PointPillars: Fast Encoders for Object Detection from Point Clouds
-
Introduction
본 논문에서는 downstream detection pipeline에 적합한 pillars라는 point cloud encoder를 제시하고자 한다. 기존의 encoder는 크게 두 가지로 나뉘는데 빠르지만 정확도가 떨어지는 fixed encoder와 느리지만 정확도가 더 높은 encoders that are learned from data로 나뉜다. Pillars는 기존의 2D conv를 사용할 수 있어 빠르고 정확도 또한 다른 encoder에 비해 높았다고 한다.
논문에서 제시한 PointPillars는 pillars마다 feature를 구하여 object의 3D oriented bounding box를 구하는 방법이다. PointPillars의 장점은 첫째로 fixed encoder를 통해 point cloud로부터 얻을 수 있는 모든 information을 활용 할 수 있다. 둘째로 voxel대신 pillars를 사용함으로써 hyper parameter로 tuning하던 vertical direction의 binning을 할 필요가 없어졌다. 마지막으로 모든 key operation이 2D convolution으로 이루어지기에 매우 빠르다.

Figure 1 KITTI dataset에서 PointPillars(PP)를 비롯한 여러 알고리즘의 성능 정리(A: AVOD, M: MV3D, C: Contfuse, V: Voxelnet, F: Frustum Pointnet, S: SECOND, P+: PIXOR++)
그래서 논문에서 제시한 main contribution을 정리하자면
-
End-to-end 3D object detection에 쓰이는 새로운 point cloud encoder인 PointPillars를 제시하였다.
-
어떻게 다른 3D OD 알고리즘에 비해 2~4배 빠르게 pillars에 2D conv를 사용하는지 보여주었다.
-
KITTI dataset에서 실험을 수행하여 3D와 BEV benchmarks에 대해 SOTA의 성능을 보였다.
-
Ablation study를 통해 strong detection performance를 보여주는 key factor가 무엇인지 알아보았다.
-
PointPillars Network

Figure 2 PointPillars의 전체적인 구조
PointPillars는 크게 3가지의 단계로 나뉜다. 1) point cloud를 sparse pseudo-image로 바꾸는 feature encoder network, 2) pseudo-image를 high-level representation으로 바꿔주는 2D conv network, 3) 3D bbox를 regression하는 detection head 부분이 있다.
2.1 Pointcloud to Pseudo-Image
2D conv 사용하기 위해 우선 point cloud를 pseudo-image로 convert하는 작업을 한다. 우선 첫째로 point cloud를 x-y plane위의 grid로 discretized 해줘서 size가 B인 pillars의 set P를 만들어 준다. Pillar는 z direction으로 spatial limit이 존재하지 않아 z dimension에서 binning을 할 hyper parameter가 필요가 없다. pillar안에 존재하는 points들은 r, xc, yc, zc, xp, yp인 parameter를 추가로 갖는다. r은 reflectance, xc, yc, zc(cluster center)는 pillar 내부에 존재하는 모든 point들의 arithmetic mean, xp, yp(pillar center)는 pillar 중심의 좌표를 의미한다. 이렇게 lidar point들이 원래 가진 x, y, z의 3가지 parameter에 새로운 6가지 parameter가 더해져서 9 dimension을 갖게 된다.
생성된 pillars는 lidar point가 sparse하기 때문에 대부분 비어있을 것이고 비지 않은 pillar 안에도 포인트가 얼마 없을 것이다. 이 sparsity는 샘플당 비어있지 않은 pillar의 수(P)와 pillar당 들어있는 point 수(N)에 제한을 두면서 (D, P, N)크기의 dense한 tensor를 정의함으로써 처리한다. 만약 sample이나 pillar가 너무 많은 data를 가지고 있어서 이 tensor의 크기를 초과한다면 data는 random하게 sample되어서 들어간다. 반대로, 너무 적은 data를 가지고 있을 경우 zero padding을 사용한다.
그 다음으로 간소화된 버전의 PointNet을 사용한다. 우선 각각의 point마다 linear layer, batch norm, ReLU를 적용하여 (C, P, N) 크기의 tensor를 생성한다. 그리고 channel에 대해 max polling을 하여 (C, P) 크기의 tensor를 생성한다. Encoding을 한 후에 original pillar의 위치로 feature들을 돌려놓아서 (C, H, W)의 pseudo-image를 생성한다.
-
Backbone
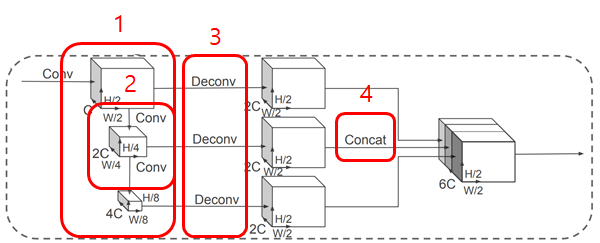
Figure 3 BackBone Network(2D conv)
VoxelNet의 3D conv와 유사한 backbone을 사용하였다. Backbone network는 두 개의 sub-network를 갖는다. Top-down network는 점점 작은 spatial resolution feature를 생성하고 두 번째 network는 이 top-down network의 feature를 up sampling하고 concatenation 한다.
이 과정을 자세히 설명하자면 Top-down backbone은 BLOCK(S, L, F)의 연속된 set(1)으로 볼 수 있다. 각각 block은 S의 stride, L개의 3x3 2D conv layer과 F개의 output channel로부터 생성된 것으로 characterize 할 수 있다. First conv layer(2)는 block의 stride size를 바꿔주기 위해 Sin/S로 stride를 한다. 그 다음의 block내의 모든 conv는 stride 1로 계산된다. 이 top-down network로부터 나온 feature를 transposed 2D conv, BN, ReLu를 이용해 up sampling UP(Sin, Sout, F)(3)을 하고 이 feature들을 concatenate(4)하여 이 결과물은 서로 다른 stride로부터 생성된 feature들의 모음이 된다.
-
Detection Head
Single Shot Detector(SSD) setup 을 사용해 3D object detection을 하였다. 2D와의 차이점은 height과 elevation이 추가된 regression target으로 사용되었다. 만약 다른 task를 하고 싶으면 detection head 대신에 다른 head로 바꾸면 된다.
-
Implementation Details
-
Network
Initialize는 uniform distribution을 사용하여 random하게 initialize하였다. Encoder Network는 C=64개의 output feature를 가졌고 car과 pedestrian/cyclist 각각에 대해 backbone은 첫 번째 block에서의 stride(S = 2 for car, S = 1 for ped/cyc)를 제외하고는 같다. 각각의 network는 3개의 Block(Block1(S, 4, C), Block2(2S, 6, 2C), Block3(4S, 6, 2C))으로 이루어져 있으며 각각의 Block들 또한 upsampling(UP1(S, S, 2C), UP2(2S, S, 2C), UP3(4S, S, 2C))을 한 후에 concatenated 되어 총 6C개의 feature가 detection head에 사용된다.
-
Loss
본 논문에서는 SECOND에서와 같은 loss function을 사용하였다. Ground truth와 anchors는 (x, y, z, w, h, l, θ)로 정의된다. localization loss는
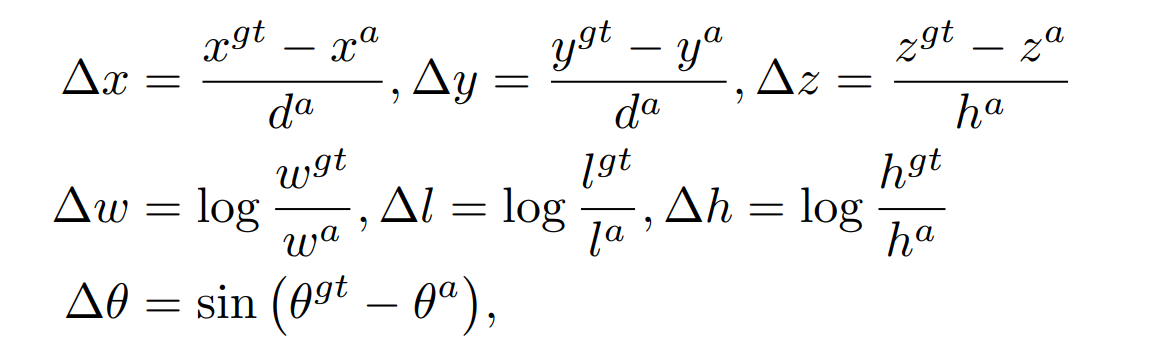

로 주어지며 angle localization 만으로는 뒤집어진 box들을 구별하지 못하므로 softmax classification을 통해 heading을 학습한다.

pa는 anchor의 class probability이며 본 논문에서는 α = 0.25, γ = 2로 세팅하였다. 따라서 total loss는 아래와 같으며

Npos는 positive anchor의 수 이고 βloc = 2, βcls = 1, βdir = 0.2 로 하였다. Loss function은 Adam으로 optimize 하였으며 initial learning rate는 2*10-4으로 15 epoch마다 0.8의 factor로 decay하였다. Epoch는 160과 320, batch size는 2와 4로 각각 validation과 test를 진행하였다.
-
Experimental setup
Dataset은 KITTI dataset을 사용하였으며 xy resolution은 0.16m로 max number of pillars per sample(P): 12000, max number of points per pillar(N): 100으로 하였다. 각각의 class anchor는 width, length, height, z center, 두 방향의 orientation(0, 90)으로 표현했다. Positive anchor와 negative anchor에 대해서만 loss를 적용하였고 NMS(IOU = 0.5)를 통해 box regression을 하였다.
Car의 경우 [(0, 70.4), (-40, 40), (-3, 1)]로 범위를 설정하였고 anchor의 경우 z center는 -1로하고 (1.6, 3.9, 1.5)로 width, length, height을 설정하였다. Positive threshold: 0.6 Negative threshold: 0.45 이다.
Ped/Cyc의 경우 [(0, 48), (-20, 20), (-2.5, 0.5)]로 범위를 설정하고 anchor의 경우 z center는 -0.6, (0.6, 1.76, 1.73)으로 width, length, height을 설정하였다. Positive threshold: 0.5 Negative threshold: 0.35 이다.
-
Data Augmentation
Data augmentation은 좋은 성능을 위해서 매우 중요하다. 우선 SECOND를 따라서 모든 3D box의 class들에 대한 ground truth와 그 3D box들 안에 속하는 point cloud에 관한 lookup table을 만든다. 그리고 각각의 ground truth sample에 대해 class별로 15, 0, 8개의 car, ped, cyc sample을 각각 뽑아서 현재 point cloud에 추가한다. 다음으로 모든 ground truth box들은 개별적으로 rotation과 translation을 통해 augmented 된다. 마지막으로 모든 point cloud와 gt box들에 대해 x축방향으로 mirroring flip을 하고 global rotation과 scaling도 적용하고 global translation도 적용한다.
-
Results
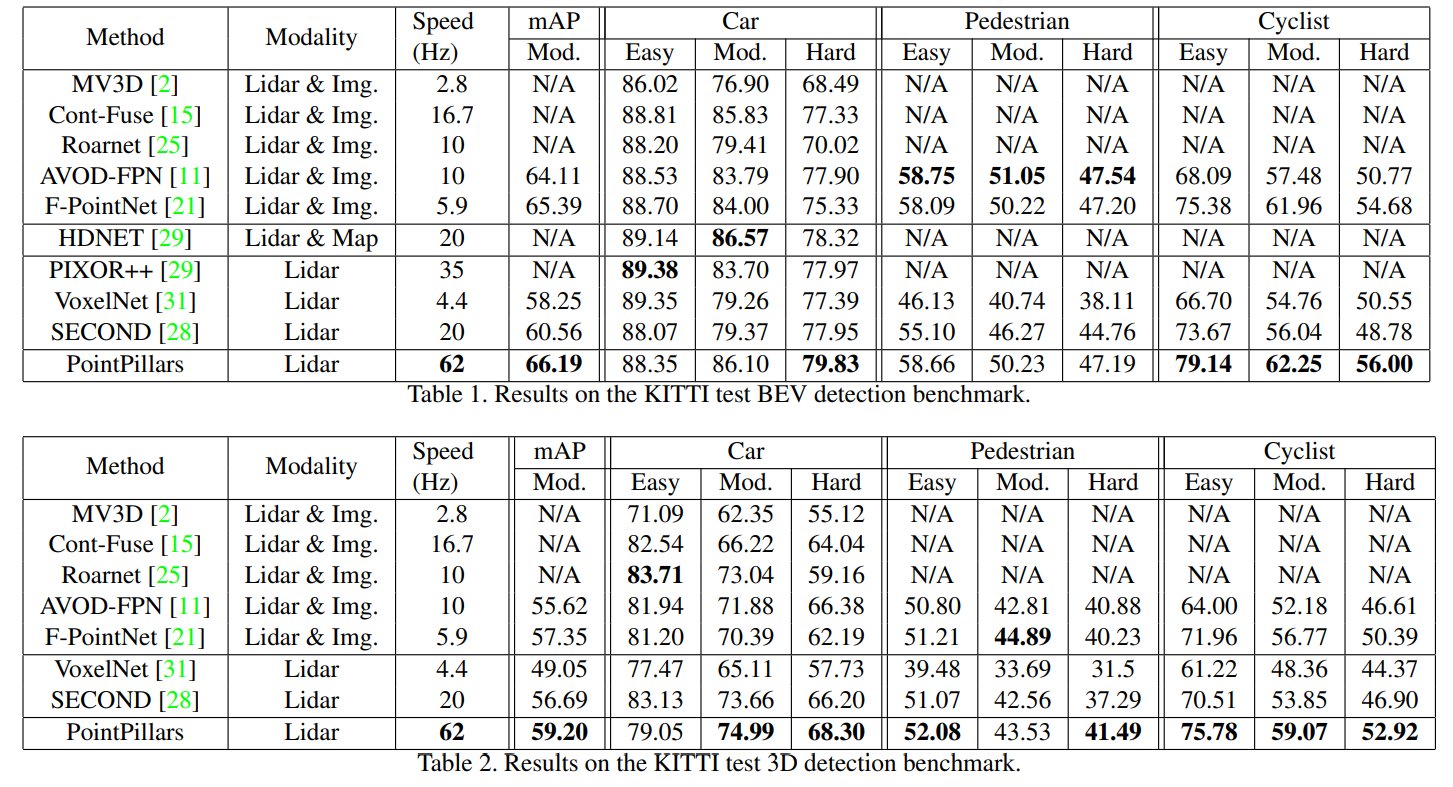

Figure 4 Quantitative Analysis
Quantitative Analysis : 속도 측면에서나 정확도 부분에서나 SOTA의 성능을 보였다. 특히속도가 압도적으로 빨랐다.

Figure 5 Qualitative Analysis
Qualitative Analysis: 둘 중에 위의 그림에서는 detection result를 보여주었고 타이트한 oriented 3D bbox를 그리는 것을 확인 할 수 있었다. 아래쪽 그림에서는 a는 car와 cyclist에 대한 false negative, b에서는 pedestrian에 대한 false positive, c에서는 detection은 올바르게 하였지만 ground truth가 저 부분에 존재하지 않은 case이며 d에서는 cyclist와 pedestrian의 label이 바뀌어서 detection하는 것을 볼 수 있다.
-
Realtime Inference
Pointpillars는 quantitative analysis에서 볼 수 있듯이 running time에서 큰 improvement를 보였다. Intel i7 CPU와 gtx 1080Ti GPU에서 실행하는 것을 기준으로 point cloud를 load하고 image상에 존재하는 point만 filtering하는데 1.7ms, pillar로 만들고 channel을 decorate하는데 2.7ms, PointPillar tensor를 GPU에 올리는데 2.9ms, encoding하는데에 1.3ms,pseudo image로 변환하는데 0.1ms, backbone과 detection heads를 실행하는데 7.7ms, CPU에서 실행되는 NMS까지 총 16.2ms가 소요된다.
Encoding단계가 실행속도를 빠르게 한 핵심단계이다. 기존에 voxelnet에서 쓰이던 encoder가 190ms, second에서 쓰이던 encoder가 48ms였는데 본 논문에서는 1.3ms로 엄청난 향상을 보였다.
그리고 유사한 디자인에서 약간의 변형을 통해서도 실행시간을 줄였는데 2개의 연속적인 pointnet의 사용 대신에 간소화된 pointnet을 사용함으로써 2.5ms를 단축하였고 encoder 크기에 맞게 첫 번째 block dimension을 64로 줄임으로써 4.5ms를 단축하였다. 그리고 upsampled feature layer의 output을 절반인 128로 줄임으로써 3.9ms를 단축하였다.
Pytorch를 통해 실험들을 진행했지만 이들을 tensor RT를 이용해 실행하였을 때 45.5%의 속도 향상이 있었다고 하였다.
Lidar의 hz가 20Hz정도로 이미 실행시간은 여유롭게 만족하지만 point pillar의 경우 fov만 사용했기에 전체적인 scene에 대해서도 빠른 실행시간 보여야 하며 autonomous vehicle의 특성상 더 낮은 computing power로도 빠른 실행시간을 보여야 하는 문제가 남아있다고 했다.
-
Ablation Studies

Figure 6 PointPillars의 다른 network들과의 비교와 speed-accuracy trade-off
-
Spatial Resolution
Spatial binning을 다양하게 하는 것은 speed와 accuracy의 trade off를 보여주었다. 작은 pillar는 보다 정확한 localization 성능과 많은 feature를 얻을 수 있었고 큰 pillar는 빠른 속도를 보였다. Car class는 bin size가 달라져도 성능이 stable하였고 성능의 감소는 주로 ped/cyc class에서 나타났다.
-
Per Box Data Augmentation
VoxelNet과 SECOND에 대해서도 대규모의 augmentation을 적용하였다. 그러나 최소한의 box augmentation이 더 좋은 성능을 보였다. 생각하기에 ground truth sampling이 box augmentation의 효과를 저하시키는 것 같았다.
-
Point Decorations
Encoder는 raw lidar point의 x, y, z, r(reflectance)를 받아 추가적인 channel을 생성한다. 이 channel을 생성함으로써 point들은 standardized된 local context를 갖게 된다. Cluster offset에 따라 standardize하는 방식을 다르게 하는데, 이는 point들을 통계적으로 summary하여 point들 사이의 dependency를 생성하는 것을 이용한다. Pillar center를 사용하는 방식은 cluster center만 사용하였을 때 data augmentation과 subsampling을 할 때 cluster center가 바뀌게 되어 높은 variance를 가지게 되는 것을 막아준다.
-
Encoding

Figure 7 Encoder에 따른 성능
PointPillar의 encoder의 성능을 따로 평가하기 위해서 SECOND의 codebase위에 여러 encoder를 적용해 보았다. 위의 그림에서 볼 수 있듯이 feature를 학습하는 encoder가 fixed encoder보다 모든 resolution에 대해서 높은 성능을 보였다. 그리고 bin size를 키움에 따른 성능변화가 현저하게 적었다.
위의 그림에 대해서 의문이 드는 것은 첫째로 원래 논문에서 MV3D와 PIXOR는 car에 대한 encoder인데 pedestrian과 cyclist에 대해서도 좋은 성능을 보이는 것과 둘째로 이 논문의 encoder가 좋은 성능을 보이긴 했지만 전체적인 네트워크를 비교한 것이 아닌 각각의 encoder만 사용하였기에 difference가 큰 것이 아닌가 싶다. 여러 요인들을 더 찾아보자면 data augmentation을 통한 성능향상과 training상의 hyperparameter의 차이, anchor box design, localization loss with 3D angle, classification loss, optimizer choice등등의 요인들도 같지 않기에 각각의 요소들에 의한 변인을 완벽히 통제하여 평가를 해야 할 필요성이 있다.
-
Conclusion
이 논문에서는 PointPillars라는 새로운 end-to-end deep network와 encoder를 제시하였다. KITTI challenge에서 정확도 면에서 SOTA의 성능을 보여주었으며 매우 빠른 속도의 detection 성능을 보여주었다.
이 논문의 코드는 https://github.com/nutonomy/second.pytorch 에 공개되어있다.
'Paper Review > Pointcloud Learning' 카테고리의 다른 글
| PointNet, PointNet++ (0) | 2021.04.10 |
|---|---|
| FlowNet3D (0) | 2021.04.10 |
| VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (1) | 2019.09.13 |